La gestion des incidents chez Yousign




Qu’est ce qu’un incident ?
C’est un événement qui arrive quand on ne s’y attend pas en règle générale 😂 et qui cause une dégradation partielle ou totale du service, dans notre cas lié à un contexte de signature électronique qualifié EIDAS qui possède plus de 8000 clients aux quatre coins du monde.
Le nombre d’incidents sur une production informatique n’est jamais de 0, comme vous vous en doutez, c’est une composante essentielle de nos métiers, c’est pourquoi on va s’efforcer de vous présenter notre nouvelle gestion des incidents.
Je vais vous donner un exemple parlant
Imaginez que vous êtes en train d’acheter votre super appartement vue mer.

Vous êtes chez votre banquier, et vous vous apprêtez à signer votre crédit pour 20 ans, quand vous voyez cette barre de chargement rester bloquée ?

On se bat quotidiennement pour ne pas que ça vous arrive 😎
Vous comprenez pourquoi nous mettons autant d’énergie dans ce processus à présent ?
Qu’est ce que la gestion des incidents ?
C’est un des processus ITIL phare :
La gestion des incidents est le processus de gestion des interruptions du service informatique et la restauration des services conformément aux accords de prestation de services (SLA).
La gestion des incidents s’étend d’un utilisateur final ou une alerte de monitoring signalant un problème jusqu’au membre d’une équipe du service d’assistance résolvant ce problème.
Nous allons dans cet article vous expliquer ce que ça veut dire chez Yousign.
Comment faisait-on jusqu’a présent ?
Les SRE ont un rôle transverse chez Yousign, ils sont garants du bon fonctionnement général de la plateforme et du bon respect des standards de production.
Que ce soit pour une problématique d’infrastructure, de sécurité, de performance ou applicative, les SRE intervenaient.
Contributeurs majeurs dès lors qu’il y a du refactoring, des migrations, etc.
Illustration de l’ancien workflow
On avait régulièrement sur Discord une douzaine de personnes lors d'un incident.
Cette raison est historique car actuellement nous sommes en train de scaler et donc mieux nous organiser.
Cela s’expliquait par :
- La taille des équipes réduite
- Les scopes pas forcément très clairement définis
Ce qui se traduisait par :
1️⃣ On voit l'alerte sur Slack, on l’acquitte sur notre alert bot OpsGenie
2️⃣ On déclenche une discussion en vocal sur Discord

3️⃣ On discute de l'incident tous en même temps sur Discord (SRE, Devs, managers)
4️⃣ On donne tout un chacun notre avis, et quelque fois on discute même de la pluie et du beau temps ⛅
Résultat : c’était d'un brouhaha incessant 🧠
Pourquoi avoir opéré ce changement ?
- Augmenter l’ownership des différents acteurs de la chaîne de création de valeur :
- Developpeur
- QA
- Data
- CISO
- Etc.
- Comme nous sommes en phase de scale, on aspire a être plus performants, pertinents quant au fait de traiter nos incidents et surtout être plus rapides pour les déceler, les corriger, en soit réduire le MTTR Mean Time To Resolve)
- Gagner en reporting pour obtenir des statistiques détaillées sur le nombre d’incidents / squads, ainsi que les délais de traitement, etc.
Comment ?
Nous avons taggué chaque alerte dans les outils suivants :
- Graylog (centralisation des logs)
- Redash (alerting SQL)
- Datadog (plateforme d’observabilité)
- Youmonit (outil interne permettant d’observer les queues RabbitMQ)
- StatusCake (synthetics monitoring)
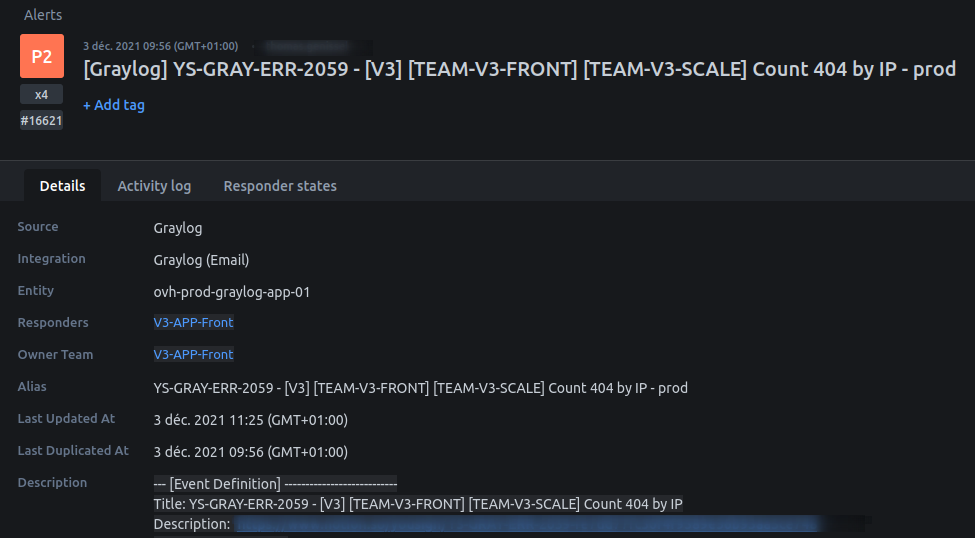
Notre convention de nommage contient :
- Le nom de l’application
- La squad qui est owner de l’alerte
- La description de l’alerte
Exemple d’une alerte
Procédure d’exploitation
Chaque alerte contient une procédure d’exploitation, ce qui permet à tous de savoir a quoi l’alerte fait référence en termes de critères de déclenchement, ainsi que la procédure de résolution, mais également le temps nécessaire théorique.
Autre avantage, offrir aux nouveaux onboardés un support leur permettant de prendre connaissance des différentes typologies d’alertes et d’incidents.
Création d’une base de données Notion
Chaque alerte possède une page Notion, qui elle-même est référencée sur une base de données Notion.
Ceci permet une recherche facilitée, et une meilleure lisibilité des alertes en les groupant suivant certains critères.
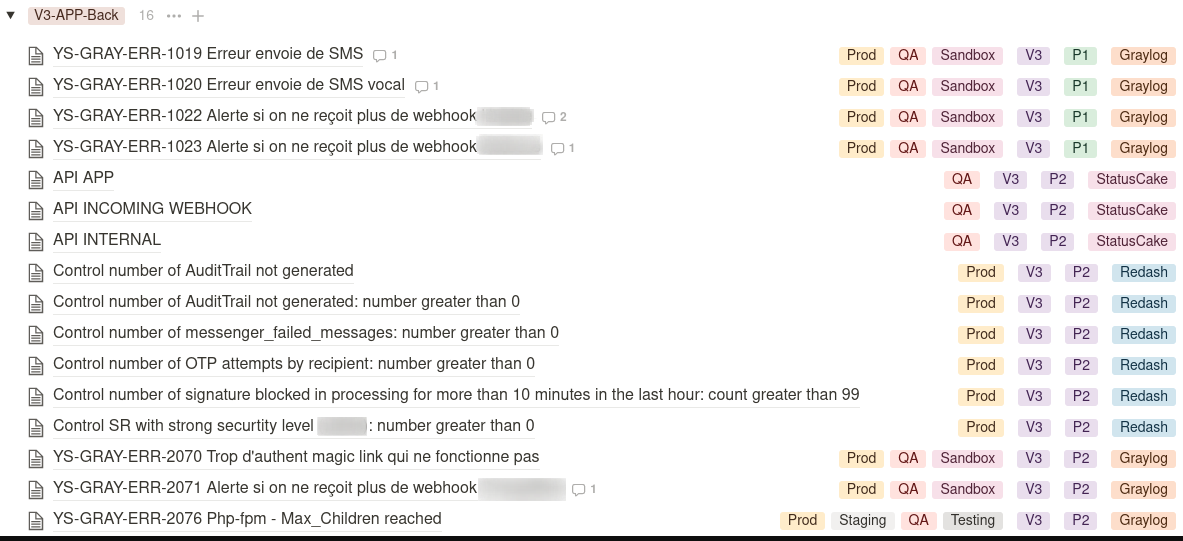
Delivery
Chaque feature doit partir en production avec des alertes pertinentes, testées auparavant et validées par l’équipe SRE, dans le cadre du production readiness qui explicite les attendus de production.
Workflow
Incident de production
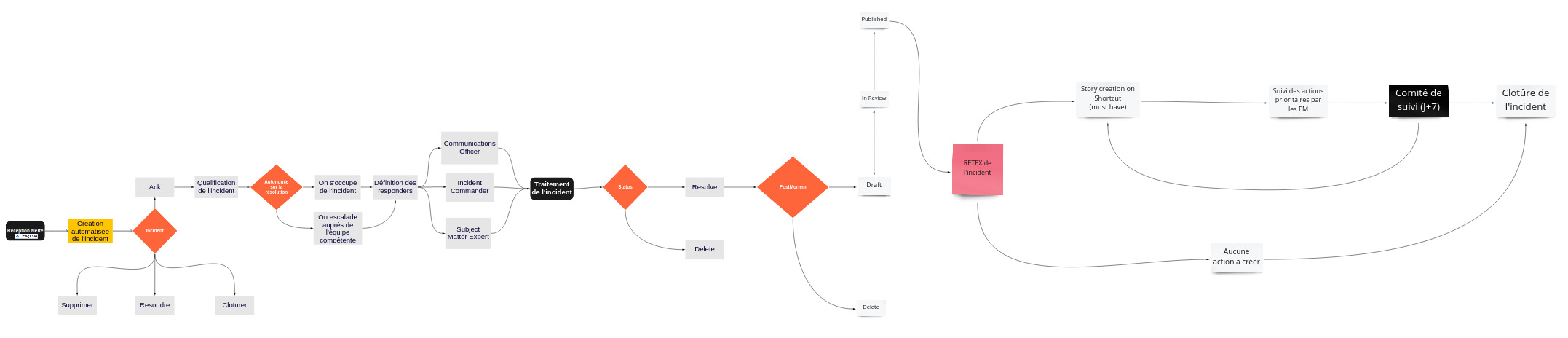
Post-mortem
Chaque incident critique donne lieu à la création d’un post-mortem.
Pour les incidents majeurs nous publions une version simplifiée de celui-ci sur notre plateforme StatusPage, ce qui permet à nos clients de connaître les raisons du dysfonctionnement et les actions que nous avons entreprises pour mitiger l’incident.
Observabilité
Pour être efficace sur la gestion d’incident, il est primordial d’être efficace sur ce que l’on observe. Sans ça on peut très vite tomber dans un des pièges suivants :
- Trop d’alertes déclenchées, ça fait mal aux yeux et à force on ne les voit plus

- Trop de fausse alertes, rend le run perméable à une erreur humaine
- Des alertes qui manquent de pertinences, vont là aussi vous faire perdre du temps précieux lors d’un troubleshooting
Quels outils avons-nous choisi ?
Opsgenie

Pour ces fonctionnalités, ses intégrations :
- Applications Android, Iphone
- 200 intégrations
- Alertes SMS, Mail, appel vocaux, Slack
- Possibilité de renommer, reclasser des alertes en fonction de différents patterns (en pré/post traitement)
- Gestion de multiples workflows (escalades en heure ouvrées, non ouvrées en fonction de patterns)
- Gestion des post-mortem (création de channel slack, activités, processus de review)
StatusPage

OpsGenie est cablé à StatusPage, ce qui nous permet entre autres :
- De créer un incident sur notre page de Status pour prévenir nos clients
- Créer un post-mortem afin de respecter nos processus SRE et communiquer aux clients la root-cause ainsi que nos actions permettant de mitiger ou résoudre l’incident
Gestion du planning d’astreinte et de RUN
Sur OpsGenie nous avons le planning d’astreinte, et de run.
Bien entendu ceux-ci sont consultables sur Google Agenda, et via l’extension Slack en quelques clics.
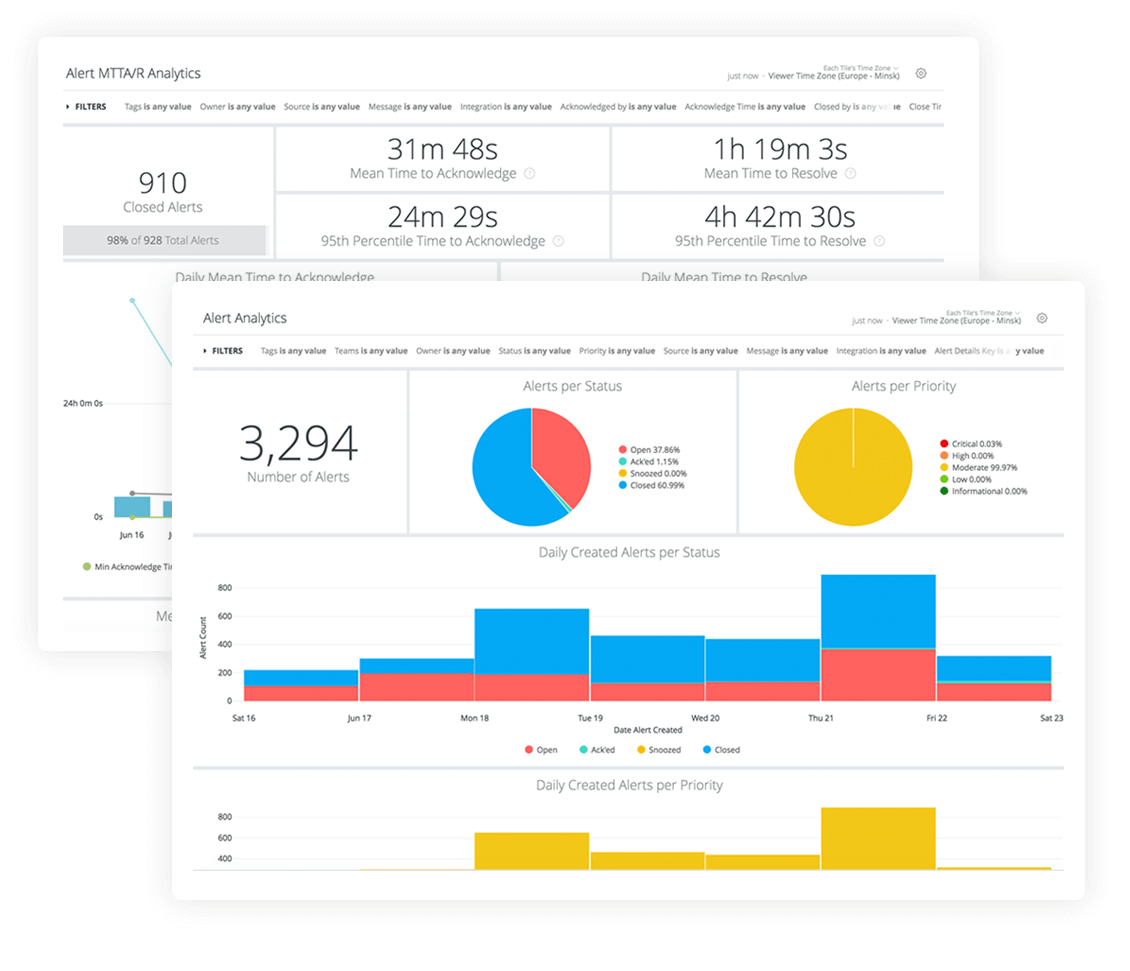
Reporting ou l’art de mesurer la performance
OpsGenie permet de générer des rapports en fonction:
- Des squads
- Des priorités
- De filtres liées aux alertes (priorité, contenu de l’alerte, etc.)
Et de bénéficier des KPI suivantes :
- Nombre d’alertes, incidents, postmortem
- MTTA
- MTTR
- Escalades
- Etc.
Onboarding
Nous proposons un cursus de formation en interne sur notre outil de gestion des incidents, mais également des vidéos pour monter en compétences sur une bonne partie de nos outils. Ce qui participe a réduire le temps de résolution, et le stress associé lors d’un incident.
Quels gains sur le moyen terme ?
Le fait de responsabiliser les squads apporte un gain incroyable au quotidien :
- Ils adaptent leurs propres alertes : revue des seuils, conditions des alertes
- Quand une squad rencontre trop souvent la même alerte, elle se concentre sur la diminution de sa fréquence (refactoring des alertes, modification du comportement applicatif, amélioration des performance, ajout de logs, etc.)
- Reporting facilité : on peut savoir quelle team rencontre le plus de problèmes, quelle application, quel temps de rétablissement, etc.
- Diminution du temps de traitement des alertes, car ce n’est plus une équipe mais un ensemble de squads
- Onboarding facilité grâce à l’alerte qui est documentée
6 conseils sur le mindset a avoir lors d’un incident
- Garder la tête froide

- Réduire le nombre de personnes dans la room au strict minimum (moins de 6 nous parait pertinent)
- Inclure le management et le customer care à votre prise de décision, pour prendre des décisions éclairées et communiquer sur l’incident (ce qui est tout un art).
- Dérouler une checklist si vous en avez une, ça rassure et permet de ne pas oublier certains items
- Créer un post-mortem au plus tôt pour que chaque acteur puisse y ajouter ses activités, ses remarques
- Si vous paniquez, demandez de l’aide, personne ne vous en voudra
- Agir et écrire sont deux rôles différents, pensez à avoir un scribe et mieux un incident manager qui s’occupera de la communication 🙂
Comment mettre en place une gestion des incidents en startup ?
- Adapter la gestion des incidents à la taille de votre structure, vos attentes produits et tech sont primordiaux 👍
- Rien n’est pire qu’un processus qui n’acquiert pas de l’adhésion auprès des équipes et du management. Fixez vous de petits objectifs (environnement de non production par exemple), puis itérez sur les niveaux de criticité au rythme de la montée en compétences des squads
- Former les Engineering managers à piloter ce processus de RUN auprès de leurs squads
- Former l’ensemble des collaborateurs tech à cet état d’esprit you build-it, you run it
- Donner de la visibilité, partagez vos victoires et vos échecs est primordial dans cette démarche transverse.
Les grandes étapes
- Choisissez un outil (OpsGenie, PagerDuty, etc.), il y a des tas de benchmarks sur le net
- Créez un projet pour créer/améliorer ce processus de gestion des incidents
- Impliquez les EM, collaborateurs en leur proposant votre vision du workflow
- Prenez en compte leurs remarques
- Implémentez l’outil de votre choix
- Implémentez votre processus
- Diffusez-le un maximum
- Formez les squads
- Recueillez le feedback des équipes
- Améliorez et itérez jusqu’à que vos KPI correspondent à vos besoins
Axes d’amélioration à venir
- Nous avons designé un workflow spécifique à la gestion de crise, et nous aimerions passer à son exécution
- Gérer la totalité des alertes via nos outils d’Infrastructure As Code (Terraform, Pulumi), car actuellement seuls 20% des alertes sont auto-provisionnés
- Un “permis” pour faire du run en production (période probatoire en pair programming, formations sur les outils de troubleshooting, test technique sur une application de démo)
- Mise en place de SLO (Service Level Objective)